Blog
How Retrieval-Augmented Generation is Transforming Knowledge-Intensive NLP Tasks in 2026
Discover how retrieval-augmented generation for knowledge-intensive NLP tasks is transforming enterprise AI.
June 17, 2026
Written by

Introduction
Everyone thought bigger AI models would solve the enterprise AI problem. They didn't.
In 2026, some of the most successful AI systems are powered by the same foundation models as everyone else. Yet their results are dramatically different. Why? Because the real competitive advantage is no longer the model. It's the ability to find, validate, and connect the right information at the right moment.
That's where retrieval-augmented generation for knowledge-intensive NLP tasks comes in. While most organizations are still focused on model upgrades, industry leaders are investing in retrieval architecture. They have learned a hard truth: an AI system is only as intelligent as the knowledge it can access.
If your AI cannot find the latest policy update, connect related information across systems, or explain where an answer came from, it is not an intelligence problem. It is a retrieval problem. And in high-stakes environments, that problem can quickly become a business risk.
This article explores why retrieval has become the defining layer of enterprise AI and how advanced RAG architectures are reshaping the future of knowledge-intensive work.
The Real Problem: Enterprise Knowledge Is Scattered Everywhere
Most organizations assume they have a model problem. In reality, they have a knowledge problem.
Think about where critical business information actually lives. Customer conversations are stored in CRM systems. Compliance updates sit inside policy documents. Product decisions are buried in meeting recordings. Financial insights are spread across spreadsheets, reports, and databases. Valuable knowledge exists everywhere, but it rarely exists in one place.
This becomes a serious challenge for modern NLP tasks. When an employee asks an AI assistant about a regulatory requirement, a customer issue, or a business process, the answer often depends on information scattered across multiple systems.
This is why many enterprise AI projects struggle after deployment. The model may be highly capable, but it cannot reason over information it cannot see. A customer support assistant might miss a recent policy update. A compliance copilot may overlook a critical document.
Traditional AI architectures were never designed to solve this problem. Systems built on approaches such as the seq2seq and encoder-decoder models transformed language processing by enabling tasks such as translation, summarization, and text generation.
The challenge facing organizations in 2026 is not generating more content. It is giving AI access to the right knowledge at the right moment. The companies succeeding with AI today are not necessarily using larger models. They are building better systems that find, connect, and validate information before generation begins.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks Has Entered a New Era
When RAG first gained traction, it was largely seen as a way to reduce hallucinations. The process was simple: retrieve relevant information, feed it to the model, and generate a response.
That approach worked for basic use cases. But as organizations deployed RAG in real-world environments, a bigger problem emerged. Most systems could retrieve information, but they couldn't understand how different pieces of information connected.
A policy document might be linked to a compliance update. A customer complaint might be tied to a product issue discussed in a separate report. Traditional RAG systems treated these as isolated chunks of text rather than connected knowledge.
The result was better search, but not necessarily better reasoning. This shift reflects a broader trend across enterprise AI, where success increasingly depends not just on model capabilities but on how organizations design, deploy, and operationalize intelligent systems at scale.
This is why the conversation has shifted. The biggest challenge in enterprise AI is no longer generating answers. It's ensuring the model receives the right context before generating them.
This is why the conversation has shifted. The biggest challenge in enterprise AI is no longer generating answers. It's ensuring the model receives the right context before generating them.

| Capability | Legacy RAG | Advanced RAG (2026) |
| Search Method | Dense vector search | Hybrid search + reranking |
| Data Structure | Text chunks | Knowledge graphs and connected entities |
| Workflow | Retrieve → Generate | Agentic and iterative retrieval |
| Data Types | Text only | Text, audio, video, code, diagrams |
| Focus | Information retrieval | Contextual reasoning and decision support |
Today, leading organizations are asking a different question: not "Which model should we use?" but "How do we consistently provide the model with the most relevant, trustworthy information?"
Three RAG Architectures Are Defining Enterprise AI in 2026
Not all RAG systems are built the same. As enterprises move beyond basic document retrieval, three architectures are emerging as the foundation of production-grade AI.
GraphRAG: Moving Beyond Text Retrieval
Traditional RAG retrieves information. GraphRAG understands relationships.
Using knowledge graph-guided retrieval augmented generation, organizations can connect entities, events, policies, and business processes instead of treating them as isolated pieces of text.
Key advantages:
- Connects information across multiple documents and systems
- Enables multi-hop reasoning and root-cause analysis
- Improves context for complex enterprise queries
- Helps uncover hidden relationships between data points
The graph RAG vs vector RAG debate is not about replacement. Vector retrieval excels at semantic search, while GraphRAG adds relationship intelligence that improves decision-making.
Agentic RAG: Making Retrieval Smarter
Early RAG systems retrieved information once and generated a response. Modern systems continuously evaluate, refine, and validate information before answering.
This is where query rewriting for retrieval-augmented large language models is becoming essential.
Key advantages:
- Rewrites vague queries into high-precision searches
- Identifies missing context before retrieval
- Validates evidence before generation
- Reduces irrelevant retrieval and prompt noise
Many enterprises now use a chain of retrieval augmented generation, where retrieval, validation, reasoning, and generation work together to improve answer quality and reliability.
Building advanced retrieval systems is only half the challenge. Scaling, monitoring, and maintaining them in production requires equally mature MLOps capabilities.
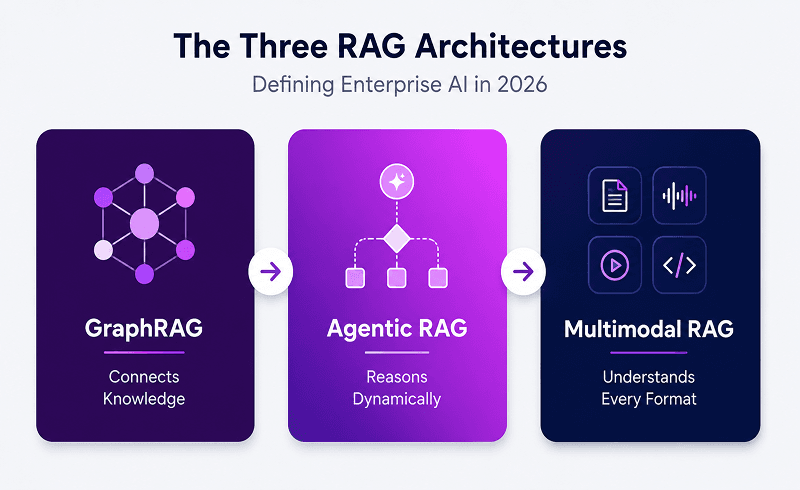
Multimodal Retrieval and Long-Term Memory
Enterprise knowledge no longer lives only in documents. It exists across videos, customer calls, diagrams, presentations, code repositories, and audio files.
Modern retrieval systems are designed to reason across all these formats.
Key advantages:
- Connects insights across text, video, audio, and visual assets
- Improves understanding of complex enterprise knowledge
- Supports cross-modal reasoning and contextual memory
- Scales efficiently across large knowledge repositories
This is where inference scaling for long-context retrieval augmented generation becomes critical. Instead of processing massive amounts of information, the system retrieves only the most relevant evidence, reducing cost while improving accuracy.
Together, these three architectures are transforming RAG from a retrieval tool into an enterprise intelligence layer.
Building a Production-Grade RAG Stack
Many organizations spend months comparing foundation models and very little time evaluating retrieval. In practice, that is often backwards.
The reality is that two companies can deploy the same model and see vastly different results. The difference usually comes down to retrieval quality, not model capability. If the model cannot access the right information, it cannot deliver reliable answers.
A production-grade RAG system requires multiple layers working together:
| Component | Purpose |
| Vector Embedding Layer | Converts content into searchable semantic representations |
| Vector Database for RAG | Stores and retrieves embeddings at scale |
| Hybrid Search Layer | Combines vector search with keyword-based retrieval |
| Reranking Layer | Prioritizes the most relevant results before generation |
| Knowledge Graph Layer | Connects entities, relationships, and business context |
| Evaluation & Governance Layer | Monitors accuracy, security, and compliance |
One of the most overlooked decisions is the vector embedding strategy. Choosing the best embedding model for RAG is not about benchmark rankings. It is about how well the model understands your organization's data.
For example:
- A legal firm needs retrieval optimized for case law and regulatory language.
- A healthcare provider requires accurate retrieval of clinical and patient data.
- A financial institution needs systems that can connect structured and unstructured information in real time.
This is why there is no universal "best" retrieval stack.
At Clarient, we've observed that many organizations overinvest in prompt engineering while underinvesting in retrieval architecture. Yet the biggest gains often come from improving retrieval relevance, contextual chunking, reranking, and knowledge organization.
The lesson is simple: better prompts may improve answers, but better retrieval improves the entire system. In 2026, retrieval architecture is becoming one of the highest-leverage investments an enterprise can make in AI.
How Advanced RAG Is Reshaping High-Stakes Industries
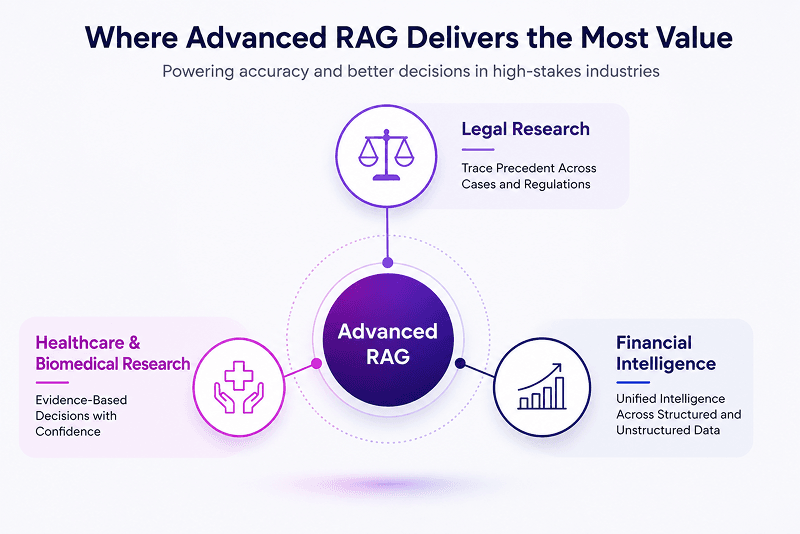
The true value of advanced RAG becomes clear in industries where accuracy, traceability, and speed directly impact business outcomes.
Legal Research
Legal teams are moving beyond keyword-based document search. Modern retrieval systems can connect case law, regulations, contracts, and precedents to surface relevant insights faster.
Business impact:
- Faster legal research and discovery
- Better precedent identification
- Reduced manual review effort
- More confident legal decision-making
Healthcare and Biomedical Research
In healthcare, an answer is only valuable if it can be backed by evidence. Advanced RAG systems help clinicians and researchers retrieve the most relevant studies, treatment guidelines, and patient information while maintaining strict governance controls.
Business impact:
- More evidence-based decision-making
- Reduced risk of unsupported recommendations
- Faster access to clinical knowledge
- Improved confidence in AI-assisted workflows
Financial Intelligence
Financial decisions depend on information scattered across reports, earnings calls, filings, market data, and internal systems. Advanced retrieval systems bring these sources together into a single intelligence layer.
Business impact:
- Faster risk assessment and analysis
- Better visibility across structured and unstructured data
- Improved regulatory and compliance reporting
- More informed investment and operational decisions
These use cases represent a much larger shift in enterprise technology. As AI systems become more capable of retrieving, reasoning, and acting on business knowledge, organizations are increasingly exploring how AI agents can automate workflows, improve decision-making, and transform day-to-day operations at scale.
How Clarient Helped Make Legal Research Faster and More Accurate
One challenge we see in knowledge-intensive platforms or workflows is that users often know what they are looking for, but still spend too much time finding the right evidence, filtering irrelevant results, and connecting related information.
Clarient addressed this challenge with an AI-powered legal research platform designed to help attorneys find contextually relevant case law faster. The platform combined AI-enabled query assistance, contextual filtering, and a scalable UX framework to improve how legal professionals searched, evaluated, and acted on case insights.
The result was a 55% reduction in legal research time, 70% improvement in search accuracy, and faster access to relevant case insights for more than 10,000 attorneys.
While the technology behind modern retrieval systems continues to evolve, the principle remains the same: AI creates value when it helps people find the right information faster and make better decisions.
The Future of Enterprise AI Will Be Built on Retrieval
As foundation models become increasingly accessible, competitive advantage is shifting away from model selection and toward knowledge architecture. The organizations creating the most value with AI are not those with the biggest models, but those that can retrieve, connect, and validate information more effectively.
This shift is already visible in the market. The global RAG market was valued at approximately $1.5 billion in 2025 and is projected to exceed $11 billion by 2030, reflecting growing enterprise demand for AI systems grounded in real-world knowledge rather than static training data.
At Clarient, we believe three trends will define the next phase of enterprise AI:
- Retrieval will become the primary differentiator as model capabilities continue to converge.
- Knowledge graphs will move into the mainstream to enable relationship-aware reasoning across enterprise data.
- Governance will be embedded into retrieval systems to ensure security, compliance, and trust from day one.
The future belongs to organizations that can turn fragmented information into trusted intelligence at scale.
Conclusion: The Future of Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Retrieval-augmented generation for knowledge-intensive NLP tasks has evolved far beyond its original role as a hallucination-reduction technique. It is now the intelligence layer that enables organizations to connect fragmented knowledge, reason across complex information, and deliver trustworthy AI experiences.
Whether through knowledge graph-guided retrieval augmented generation, advanced query rewriting, multimodal retrieval, or adaptive reasoning workflows, the future of enterprise AI belongs to organizations that treat retrieval as a strategic capability rather than a technical feature.
If your AI initiatives are struggling with inconsistent answers, fragmented data, or limited business impact, the issue may not be the model. It may be the retrieval layer behind it.
Clarient helps organizations build retrieval-first AI systems that improve answer quality, accelerate decision-making, and turn enterprise knowledge into a measurable competitive advantage. Connect with our team to explore what's possible.
Frequently Asked Questions
What is RAG vs LLM?
A Large Language Model (LLM) generates responses based on patterns learned during training, while Retrieval-Augmented Generation (RAG) retrieves relevant external information before generating an answer. This makes RAG more suitable for knowledge-intensive environments where information changes frequently.
For enterprise use cases, the difference is significant. An LLM may rely on historical training data, while a RAG system can access current documents, databases, policies, and proprietary knowledge sources. This improves accuracy, transparency, and source grounding.
In practice, organizations increasingly combine Large Language Models and AI frameworks with advanced retrieval systems to create AI applications that can reason over real-time business knowledge rather than relying solely on static training data.
What is a RAG pipeline?
A RAG pipeline is the workflow that retrieves relevant information from external sources and provides it to a language model before generating a response. Typical stages include data ingestion, indexing, retrieval, reranking, and response generation.
A Simple Guide to Retrieval-Augmented Generation
Retrieval-Augmented Generation combines information retrieval with language generation. Instead of asking a model to answer solely from memory, the system first searches relevant knowledge sources and then uses that information to generate a response.
A typical implementation includes a vector embedding model, a vector database for RAG, a retrieval layer, and a language model. When a user submits a query, the system retrieves the most relevant content and uses it as context for generating an answer.
This approach helps reduce hallucinations, improves answer accuracy, and enables organizations to build AI systems that can work with proprietary, domain-specific, and constantly changing information.
What is GraphRAG?
GraphRAG is an advanced retrieval approach that combines knowledge graphs with retrieval systems. Unlike traditional vector search, it understands relationships between entities, concepts, and documents, enabling multi-hop reasoning across connected data.
GraphRAG vs Vector RAG: What is the difference?
The GraphRAG vs Vector RAG debate centers on retrieval strategy. Vector RAG excels at semantic similarity search, while GraphRAG uses entity relationships and knowledge structures to answer complex analytical questions that require contextual connections.
When should you use vector embeddings?
Vector embeddings are useful for semantic search, recommendation systems, document retrieval, similarity matching, and retrieval-augmented AI applications. They help systems understand meaning rather than relying only on keyword matching.
What is the best embedding model for RAG?
There is no universal best embedding model for RAG. The right choice depends on your domain, language requirements, retrieval objectives, latency constraints, and evaluation metrics. Testing models against your own data typically produces better results than relying on benchmark scores alone.
What is query rewriting for retrieval-augmented large language models?
Query rewriting for retrieval-augmented large language models is the process of reformulating user questions to improve retrieval accuracy. The system converts vague or ambiguous queries into optimized search requests that retrieve more relevant context.
What is a chain of Retrieval-Augmented Generation?
A chain of Retrieval-Augmented Generation refers to a multi-step workflow where retrieval, validation, reasoning, and generation occur sequentially. This approach improves answer quality by ensuring the model uses verified, relevant evidence before generating responses.
Who can implement governance for Retrieval-Augmented Generation?
Governance for Retrieval-Augmented Generation is typically implemented by a combination of AI engineers, data architects, security teams, compliance officers, and platform administrators.
Effective governance goes beyond model behavior. It includes access controls, data lineage, audit logging, retrieval permissions, content validation, and evaluation frameworks. Organizations operating in regulated sectors such as healthcare, finance, and legal services often require governance controls at every stage of the retrieval pipeline.
As enterprise adoption grows, governance is becoming a foundational requirement rather than an optional feature. The most successful RAG deployments integrate governance directly into the retrieval layer, ensuring users access only authorized information while maintaining transparency and compliance.
What are knowledge graph tools?
Knowledge graph tools help organizations create, manage, and query relationships between entities, concepts, and documents. These tools are commonly used in knowledge graph-guided retrieval augmented generation systems to support contextual search and multi-hop reasoning.
How do Large Language Models and AI frameworks support modern RAG systems?
Modern RAG systems combine Large Language Models and AI frameworks with retrieval infrastructure to create reliable enterprise applications. Frameworks such as LangGraph and LlamaIndex help orchestrate retrieval workflows, agentic reasoning, memory management, and tool integration.
These frameworks also support advanced capabilities such as query rewriting, contextual chunking, reranking, and multimodal retrieval. Rather than acting as standalone chat interfaces, they provide the orchestration layer that connects retrieval systems with language models.
As organizations adopt more sophisticated AI architectures, these frameworks play a critical role in enabling inference scaling for long-context retrieval-augmented generation, ensuring that models can efficiently reason over large volumes of information without incurring high computational costs.
How do traditional NLP architectures relate to modern RAG systems?
Traditional NLP tasks often relied on architectures such as the seq2seq and encoder-decoder models for translation, summarization, and text generation. While these approaches remain important foundations, modern RAG systems extend them by incorporating external knowledge retrieval, enabling more accurate and context-aware responses.
Written by

Parthsarathy Sharma
With 4+ years of experience across AI, UX, enterprise technology, and brand strategy, Parthsarathy brings a research-driven lens to digital experience content. His work focuses on turning emerging technology, customer experience, and business trends into clear, practical perspectives for readers.
Share
Are you seeking an exciting role that will challenge and inspire you?

GET IN TOUCH